|
CUV
0.9.201304091348
|
|
CUV
0.9.201304091348
|

|
Functions | |
| template<class V , class M , class L > | |
| void | cuv::libs::opt::softmax (cuv::tensor< V, M, L > &dst, const cuv::tensor< V, M, L > &src, unsigned int vardim=1) |
| calculate derivative of softmax. | |
| template<class V , class M , class L > | |
| void | cuv::libs::opt::softmax_derivative (cuv::tensor< V, M, L > &dst, const cuv::tensor< V, M, L > &softmax_act, const cuv::tensor< V, M, L > &residual, unsigned int vardim=1) |
| calculate derivative of softmax. | |
| template<class V , class M , class L > | |
| void | cuv::libs::opt::adagrad (tensor< V, M, L > &W, const tensor< V, M, L > &dW, tensor< V, M, L > &sW, const float &learnrate, const float &delta, const float &decay=0.0f, const float &sparsedecay=0.0f) |
| Do a gradient update step using AdaGrad. | |
| template<class V , class M , class L > | |
| void | cuv::libs::opt::rmsprop (tensor< V, M, L > &W, const tensor< V, M, L > &dW, tensor< V, M, L > &sW, const float &learnrate, const float &delta, const float &decay=0.0f, const float &sparsedecay=0.0f, const float &grad_avg=0.9f) |
| Do a gradient update step using RMSPROP. | |
| void cuv::libs::opt::adagrad | ( | tensor< V, M, L > & | W, |
| const tensor< V, M, L > & | dW, | ||
| tensor< V, M, L > & | sW, | ||
| const float & | learnrate, | ||
| const float & | delta, | ||
| const float & | decay = 0.0f, |
||
| const float & | sparsedecay = 0.0f |
||
| ) |
Do a gradient update step using AdaGrad.
| W | Destination matrix |
| dW | The gradient of W. This is a tensor of same shape as W. |
| sW | The sum of the squared gradients for each component as W (therefore also same shape as W). |
| learnrate | Scalar learnreate |
| delta | added in denominator of adagrad |
| decay | (optional) Scalar L2 penalty |
| sparsedecay | (optional) Scalar L1 penalty |
| void cuv::libs::opt::rmsprop | ( | tensor< V, M, L > & | W, |
| const tensor< V, M, L > & | dW, | ||
| tensor< V, M, L > & | sW, | ||
| const float & | learnrate, | ||
| const float & | delta, | ||
| const float & | decay = 0.0f, |
||
| const float & | sparsedecay = 0.0f, |
||
| const float & | grad_avg = 0.9f |
||
| ) |
Do a gradient update step using RMSPROP.
| W | Destination matrix |
| dW | The gradient of W. This is a tensor of same shape as W. |
| sW | The sum of the squared gradients for each component as W (therefore also same shape as W). |
| learnrate | Scalar learnreate |
| delta | added in denominator of rmsprop |
| decay | (optional) Scalar L2 penalty |
| sparsedecay | (optional) Scalar L1 penalty |
| avg_grad | time constant to average gradient squares with (0.9 means keep most of old average) |
| void cuv::libs::opt::softmax | ( | cuv::tensor< V, M, L > & | dst, |
| const cuv::tensor< V, M, L > & | src, | ||
| unsigned int | vardim = 1 |
||
| ) |
calculate derivative of softmax.
Calculates the SoftMax function 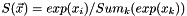 for
for 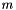 multinomial variables with
multinomial variables with 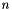 values.
values.
@param dst the value of \form#8 of size \form#9
@param src the input values to be softmaxed
| vardim | the dimension in which the variables are stored |
| void cuv::libs::opt::softmax_derivative | ( | cuv::tensor< V, M, L > & | dst, |
| const cuv::tensor< V, M, L > & | softmax_act, | ||
| const cuv::tensor< V, M, L > & | residual, | ||
| unsigned int | vardim = 1 |
||
| ) |
calculate derivative of softmax.
Calculates the derivative of SoftMax function for multinomial variables with values.
@param dst destination tensor of size \form#10
@param softmax_act the value of \form#8 of size \form#9
| residual | the residual of size 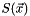 , also size , also size 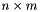 |
| vardim | the dimension in which the variables are stored |
 1.8.1.2
1.8.1.2

